

| 前页 | 后页 |
代码分析器
对于每天处理源代码的人来说,代码分析器是必不可少的工具。
它可以在本地或 Sparx 英特尔云服务上以闪电般的速度对源代码存储库执行非常复杂的查询。查询是使用 Sparx系统开发的高级语言组成的。该语言使用易于学习的小而富有表现力的词汇表,并且允许比传统方法更快地查询代码指标。
访问
|
功能区 |
开发 >源代码 > 代码分析器 |
代码分析器菜单
当您单击窗口左上角的![]() 图标时,将显示代码分析器菜单。
图标时,将显示代码分析器菜单。
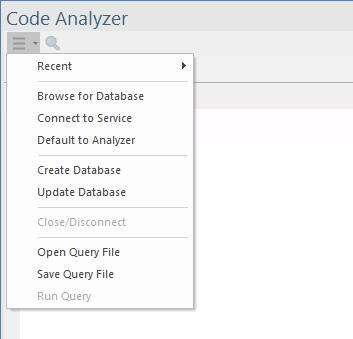
该菜单为与代码分析器的使用相关的活动提供各种命令,包括选择要使用的代码代码矿工数据库、更新代码矿工数据库和打开代码矿工查询文件进行编辑。
此表描述了每个菜单命令。
命令 |
描述 |
|---|---|
|
最近的 |
显示一个子菜单,提供最近连接到服务和本地数据库文件的列表。 |
|
浏览数据库 |
显示“文件选择器”对话框,允许您浏览机器上的代码矿工数据库。 |
|
连接到服务 |
显示“代码矿工数据库连接”对话框,您可以在其中指定(列表)代码矿工数据库服务的连接详细信息。 |
|
默认为分析器 |
选择此选项会导致代码脚本在启动代码分析器自动连接到为活动执行分析器分析器配置的代码矿工服务。 |
|
创建数据库 |
显示“创建代码矿工数据库”对话框,允许您从文件系统中的源代码存储库创建代码矿工数据库。 |
|
更新数据库 |
显示“代码矿工数据库更新”对话框,该对话框允许您对现有代码矿工数据库执行增量更新,以合并对源代码文件的最新更改。 |
|
关闭/断开 |
关闭或断开与代码矿工数据库库或服务的连接。 |
|
打开查询文件 |
显示“文件打开”对话框,允许您从文件系统中选择 mFQL 查询文件。 |
|
保存查询文件 |
显示“文件保存”对话框,允许您将当前 mFQL 查询保存到命名文件。 |
|
运行查询 |
运行在“查询”选项卡编辑器中输入的整个查询或查询的选定内容。 快捷键 F6。 |
使用分析器之前
在您可以使用代码分析器,您必须首先创建一个代码矿工数据库或找到代码分析器可以访问的现有数据库。这里总结了创建代码矿工数据库,或者您可以阅读帮助主题创建新代码矿工数据库帮助的详细说明。
根据您将使用的库的位置,您应该:
- 选择要使用的代码矿工库文件,或
- 连接到托管代码矿工数据库的服务。
创建代码矿工数据库
代码矿工数据库是从源代码存储库构建的。该过程类似于代码编译,使用语言语法分析单个文件。
有两种类型的构建——完整的和增量的。最初的完整构建可能需要一些时间,但随后的增量构建非常快。
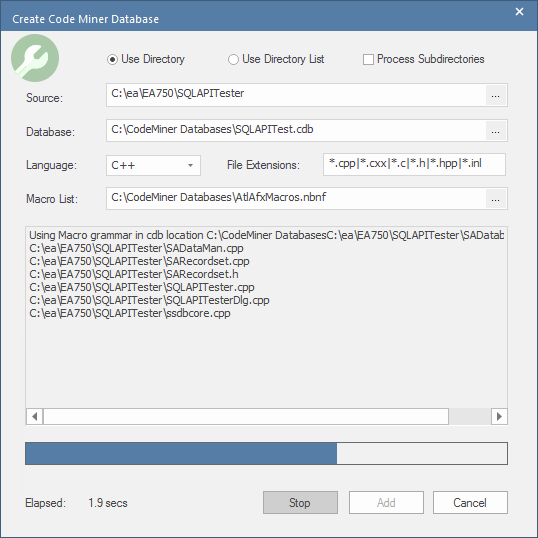
使用目录作为输入
您可以选择单个文件夹作为要编译的源代码的根。使用此选项,您可以选择包含子目录
使用目录列表
有时,您想使用多个项目,但并非所有项目都在一个目录下。在这种情况下,您可以创建一个文本文件,列出您要包含的每个文件夹的完整路径,并在“源”字段中指定该文本文件。每个目录路径都应列在单独的行上。
c:\myprojects\project1\tools\scintilla
c:\myprojects\project2\src
d:\mylibs\lib1\src
如果要递归处理目录中的子目录,请在路径前加上感叹号,如下所示:
!d:\mylibs\lib1\src
任何以 # 字符开头的行都被视为注释。
# 包括闪烁
c:\myprojects\project1\tools\scintilla
语
在此字段中,您指定用于构建此代码矿工数据库的源代码中使用的语言。
可用的语言有:C++、C#、 Java 、XML、MDGTechnology 和 Custom。
宏列表
When the language selected is 'C++', the 'Macro List' selection field is displayed .对于C++来说,信息编译到数据库中的成功和深度与宏的使用有着千丝万缕的联系。此字段可用于选择将用作编译的辅助语法组件的 nBNF 宏文件。
默认情况下,宏文件将默认为Enterprise Architect安装文件夹中的宏文件。您可以自由修改或扩展此文件的内容以满足您的要求 - 例如,当您需要更正编译log文件中报告的错误时。
语法
Sparx Systems为下拉选择列表中列出的所有语言开发了语法; C++、C#、 Java 、XML 以及 MDGTechnology。对于这些语言,使用内置语法文件。
还有一个选项可以选择“自定义”语言。选择“自定义”时,将显示“语法”字段。此字段用于指定包含自定义语言语法的文件。然后代码矿工将使用该语法来解析以该语言编写的源代码。
开发自定义语言的用户需要指定该语言的语法规则并将它们保存到 nBNF 文件中。 Enterprise Architect的语法编辑器专为此目的而设计。
The帮助主题语法框架提供了有关编写帮助语法的详细信息。
更新代码矿工数据库
有时,您会想要更新您的代码矿工数据库。通常,当您对源代码进行更改时,以及在更新语法文件或扩展宏文件之后。
更新数据库的过程与创建新数据库非常相似,但速度更快,因为您不是从头开始。只需选择菜单选项“更新数据库”。将显示“代码矿工数据库更新”对话框。输入字段将使用上次构建的值填充。继续“创建代码矿工数据库”。
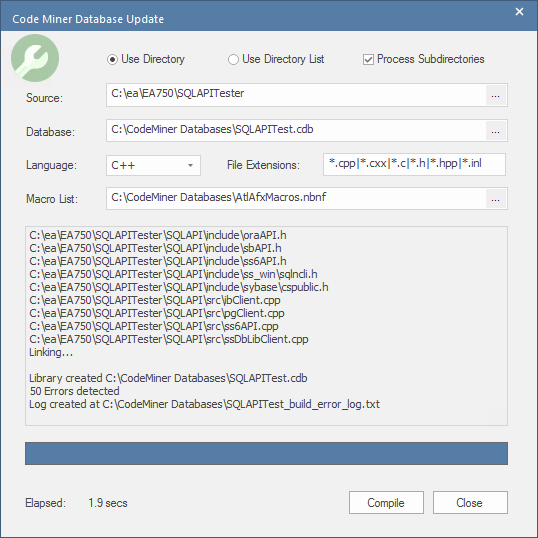
选择一个代码矿工数据库文件
如果您选择为您的代码矿工数据库使用库文件,请选择菜单选项“浏览数据库”。这将显示一个“文件选择器”,您可以在其中浏览并选择一个 *.cdb 文件。
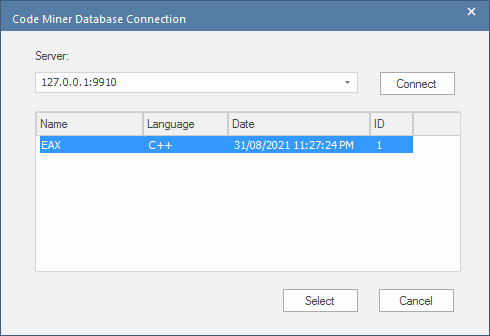
连接到服务
连接到服务时,对话框会列出该服务托管的所有数据库。
您可以选择在列表中选择单个数据库,或者只需单击“选择”按钮,在这种情况下,将在服务列出的所有数据库中执行查询。
运行查询
连接到代码矿工数据库后,您就可以开始运行查询了。
要运行查询,请选择代码分析器窗口中的查询选项卡,输入您的查询,然后单击![]() 图标执行查询。
图标执行查询。
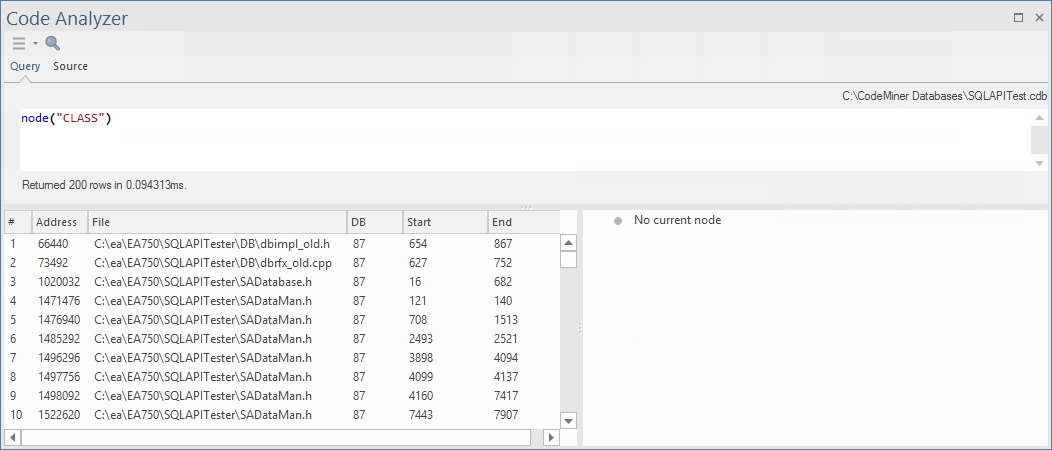
在此示例中,我们运行了一个简单的查询节点( “CLASS” ),它将返回在代码矿工数据库中找到的所有“类”节点。
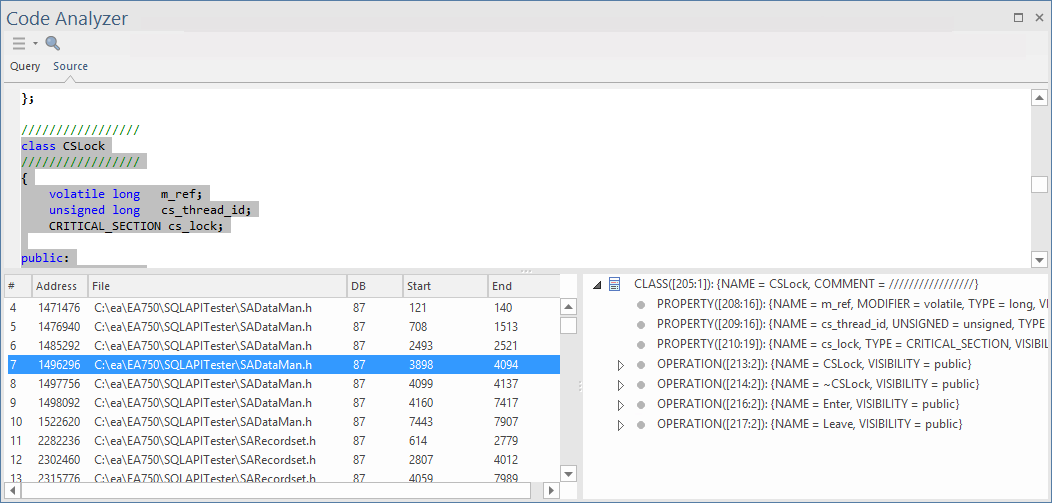
通过在左下方面板中选择一个结果,“源”选项卡被激活并显示与所选节点对应的源代码。该类节点的详细信息显示在右下方面板中。
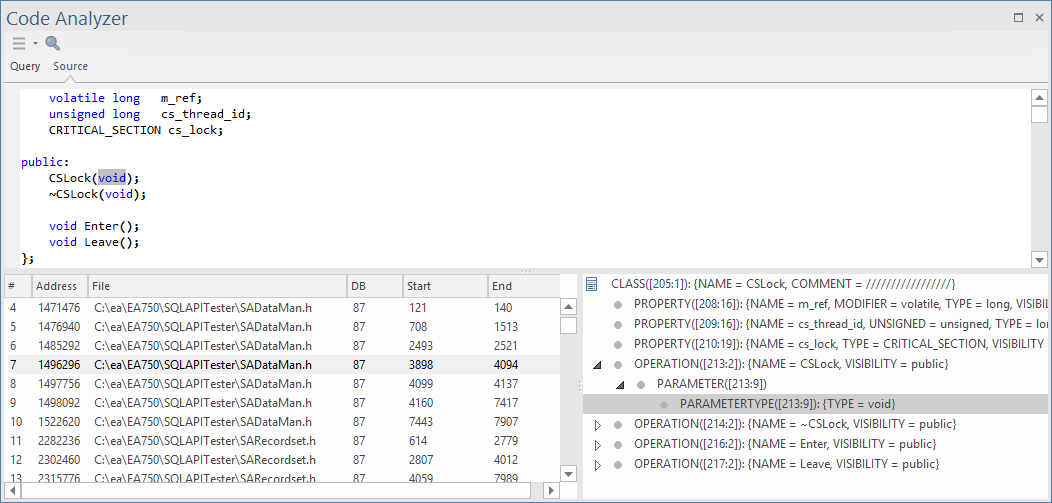
在右下角面板中选择一个细节项,会缩小源代码中的选择范围,如此处所示。
Query Example - Intersection
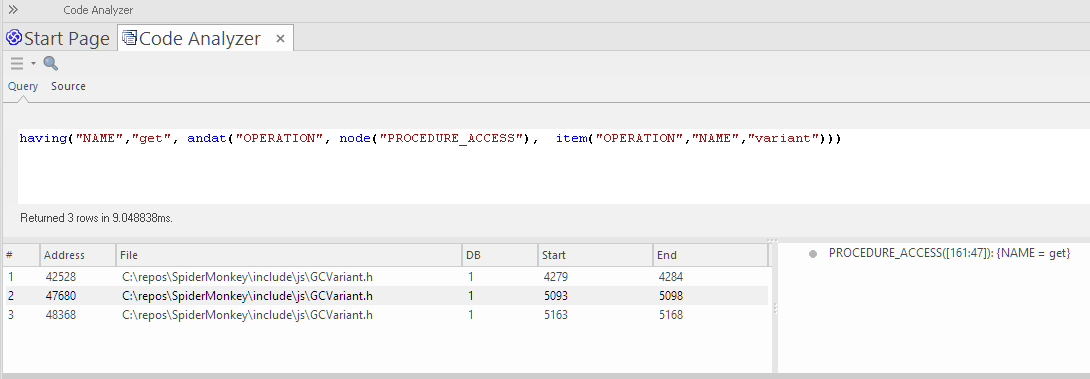
As an example, this mFQL query finds all the classes that have an operation named GetOption.andat( "CLASS", item("OPERATION", "NAME", "GetOption"), node("CLASS"))
This clause returns a set of operations for which the 'NAME' value is "GetOption":
item("OPERATION", "NAME", "GetOption")
This clause returns a set of all Class nodes:
node("CLASS")
Formal syntax:
andat( string:rule, set:left, set:right)
'andat' takes the set of operations (left), applies the rule "CLASS" (only include rows that have a CLASS parent), then intersects that set with the set of all known classes (right). If the intersection succeeds, the operation node is added to the result set, otherwise it is excluded.
查询语言 - mFQL
代码分析器使用的查询语言在代码矿工查询语言 (mFQL) 帮助分析器帮助有完整描述。
此处还提供A简要说明和一些示例。
mFQL 语言基于集合。每个语句都使用各种类型的集合操作,其中只有少数。